<property> <name>dfs.nameservices</name> <value>sync</value> <description>Logical name for this new nameservice</description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file://home/wudi/hadoop/nn</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://host1:port1;host2:port2;host3:port3/sync</value> </property>
public static final String SPLIT_MINSIZE_PERNODE = "mapreduce.input.fileinputformat.split.minsize.per.node"; public static final String SPLIT_MINSIZE_PERRACK = "mapreduce.input.fileinputformat.split.minsize.per.rack";
/** * Created by xiaoyue26 on 17/9/14. * <p> * 不接受压缩. 要修改为接受压缩的话,需要学LineRecordReader再修改. * 只支持utf-8 */ public class XmlInputFormat extends TextInputFormat {
public static final String START_TAG_KEY = "xmlinput.start"; public static final String END_TAG_KEY = "xmlinput.end";
/** * XMLRecordReader class to read through a given xml document to output xml * blocks as records as specified by the start tag and end tag */ public static class XmlRecordReader implements RecordReader<LongWritable, Text> { private final byte[] startTag; private final byte[] endTag; private final long start; private final long end; private final FSDataInputStream fsin; private final DataOutputBuffer buffer = new DataOutputBuffer();
// open the file and seek to the start of the split start = split.getStart(); end = start + split.getLength(); Path file = split.getPath(); FileSystem fs = file.getFileSystem(jobConf); fsin = fs.open(split.getPath()); //先定位到文件此次的开头 fsin.seek(start); }
// 捞出 偏移量key,文本value @Override public boolean next(LongWritable key, Text value) throws IOException { if (fsin.getPos() < end) { if (readUntilMatch(startTag, false)) { try { //存一下startTag buffer.write(startTag); if (readUntilMatch(endTag, true)) { key.set(fsin.getPos()); value.set(buffer.getData(), 0, buffer.getLength()); return true; } } finally { buffer.reset(); } } } return false; }
@Override public LongWritable createKey() { return new LongWritable(); }
@Override public Text createValue() { return new Text(); }
@Override public long getPos() throws IOException { return fsin.getPos(); }
@Override public synchronized void close() throws IOException { if (fsin != null) { fsin.close(); }
// 11. IO操作 def srcFile = new File('/Users/xiaoyue26/input') srcFile.eachLine { println it } // 写入 def targetFile = new File('/Users/xiaoyue26/output') targetFile.withOutputStream { os -> srcFile.withInputStream { ins -> os << ins } }
hello9.configure { description = "this is hello9" }
配置在定义后,但依然能打印出this is hello9. 一个Task除了执行操作之外,还可以包含多个Property,其中有Gradle为每个Task默认定义的Property,比如description,logger等。另外,每一个特定的Task类型还可以含有特定的Property,比如Copy的from和to等。当然,我们还可以动态地向Task中加入额外的Property。
# 反复进行上述步骤,直到出现提示: >18ed2ac1522a014412d4303ce7c8db39becab076 is the first bad commit commit 18ed2ac1522a014412d4303ce7c8db39becab076 Author: Robert Bittle <guywithnose@gmail.com> Date: Mon Apr 23 06:52:10 2012 -0400
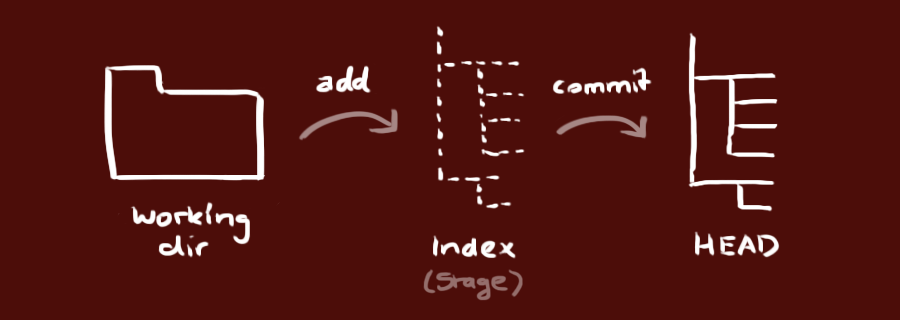
##添加和提交 你可以提出更改(把它们添加到暂存区),使用如下命令:
add
1
git add *
这是 git 基本工作流程的第一步;使用如下命令以实际提交改动:
commit -m "代码提交信息"```
1 2 3 4 5
现在,你的改动已经提交到了 `HEAD`,但是还没到你的远端仓库。
##推送改动 你的改动现在已经在本地仓库的 HEAD 中了。执行如下命令以将这些改动提交到远端仓库: ```git push origin master
894a16d HEAD@{0}: commit: commit another todo 6876e5b HEAD@{1}: checkout: moving from solve_world_hunger to kill_the_batman 324336a HEAD@{2}: commit: commit todo 6876e5b HEAD@{3}: checkout: moving from blowup_sun_for_ransom to solve_world_hunger 6876e5b HEAD@{4}: checkout: moving from kill_the_batman to blowup_sun_for_ransom 6876e5b HEAD@{5}: checkout: moving from cure_common_cold to kill_the_batman 6876e5b HEAD@{6}: commit (initial): initial commit
.png "存储架构")
.png "故障恢复")
.png "Lineage")
.png "Lineage")
.png "Lineage")
.png "数据分享")
